Fundamentos de la web semántica
Perfilado de sección
-
-
Objetivos de la Unidad
Entender las limitaciones de XML como modelo de datos semántico.
Comprender lo que es un grafo de conocimiento y poder modelar una realidad utilizando RDFS.
Construyendo la Web de Datos
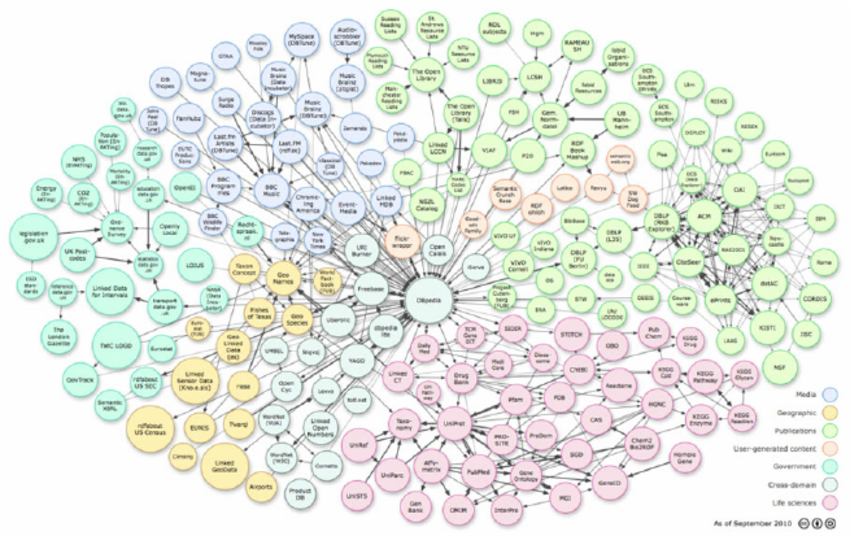
Relación de esta Unidad con lo que estudiamos en la Unidad anterior:
En la unidad anterior repasamos los Modelos de Datos. Estudiamos XML Schema como modelo para validar tipos de documentos. Comparamos el Modelo Relacional y el Modelo Orientado a Objetos según el nivel de abstracción que ofrecen. Diferenciamos el nivel de abstracción que tienen los modelos de su capacidad de expresión. Recordemos que la capacidad de expresión está en relación con cuánta semántica del mundo real es capaz de representar el modelo. En esta unidad estudiaremos el modelo de Grafos de Conocimiento como uno de los modelos de mayor capacidad de expresión que XML. Nos interesa entender lo que es la Web Semántica, también llamada Web de Datos o Web 3.0. En la unidad anterior terminamos con un dibujo en capas de los elementos necesarios para la catalogación de libros en las bibliotecas en correspondencia con los elementos que hacen a la Web Semántica. En esta unidad profundizaremos en lo que significa la capa RDF de ese stack de tecnologías de la Web Semántica, identificando a RDF como un tipo de grafo de conocimientos.
Contenido de la Unidad
Parte I: Modelos Semánticos
-
¿Qué limitaciones tiene XML para la Web de Datos?
-
Grafos de Conocimientos (Knowledge Graphs)
2.1 El panel de conocimientos de Google
2.2 Características de un grafo de datos
2.3 Diferencias entre un grafo de conocimientos y un grafo de datos
2.4 Grafos de Conocimiento en el mundo real
Parte II: RDF: un tipo de Grafo de Conocimientos
¿Cómo nombrar los datos en la Web?
RDF: conceptos, sintaxis y semántica
2.1 Definición del modelo abstracto de RDF
2.2 RDF serializaciones
2.3 Representando hechos simples con RDF
2.4 RDF Schema/RDF vocabulario
2.5 Inferencia en RDF
2.6 Semántica de RDF
-
-
No olvides seleccionar el botón "terminar" y el botón "terminar revisión" cuando tengas completa la actividad.
-
Si realizaste la actividad AI1 en las conclusiones encuentras las dos grandes limitaciones de XML.
Por supuesto, XML es a pesar de estas limitaciones uno de los pilares de la Web Semántica.
XML tiene muchas características que lo hacen fundamental para su uso en la Web. Entre ellas podemos destacar que facilita el intercambio de información entre fuentes tecnologicamente heterogéneas y es facil de entender tanto por humanos como por mas máquinas. Su aplicación fundamental es la representación estructural de los datos y la fácil distribución de los mismos. Otras cualidades destacables de XML es que existen complementos como XQuery, Xpath, XSLT y XML Schema (XSD) para consultar, navegar, transformar y validar los datos representados en un documento XML.
Un ejemplo para mostrar este potencial podría ser el de dos instituciones médicas A y B con sistemas tecnologicamente diferentes que intercambian información de sus afiliados cuyos datos son almacenados en bases de datos heterogéneas. En este caso, la institución A puede solicitar los datos de los nuevos afiliados a partir de una fecha determinada a un servicio expuesto por la institución B el cual recupera de su base local los registros de sus afiliados, los serializa en un documento XML y los devuelve a la institución A. Luego la institución A puede validar la consistencia del documento usando un archivo de definición de esquemas XML Schema, y en caso de ser correcto procesarlo usando XQuery y XPath para luego persistirlos en su base local. Adicionalmente la institución B puede utilizar XSLT para transformar el documento XML en una página web o mostrar a un administrador.
Por todo esto XML juega un papel fundamental en la web de datos abiertos y la integración de sistemas.
Sin embargo, XML presenta carencias cuando lo que queremos modelar son relaciones conceptuales y no sólo la estructura de documentos.
Entonces podemos decir que XML es necesario pero no suficiente! Y es allí donde aparecen construcciones más ricas semánticamente como los Grafos de Conocimiento (Knowledge Graphs), y en especial RDF.
“In short, XML allows users to add arbitrary structure to their documents but says
nothing about what the structures mean”
De: XML and the Second-Generation Web. Jon Bosak, Tim Bray. Scientific American, Mayo 1999.
-
-
Video de presentación de Google cuando lanzaron el Panel de Conocimiento explicando el uso del "Grafo de Conocimiento" en el 2012.
Actualmente el grafo representa recursos mucho más interactivos que al comienzo. Si se busca por ejemplo un negocio se puede obtener la franja horaria con indicaciones de las horas más ocupadas.
Es interesante buscar distintos recursos en la web, como grupos musicales, artistas, alojamientos y comparar con lo que anuncia el video de hace 8 años. Observen por ejemplo que también se muestran en el panel actual las redes sociales donde un artista tiene presencia y recomendaciones relacionadadas.
-
Parte II. RDF: un tipo de Grafo de Conocimientos
 Objetivo:Estudiar la forma en que RDF identifica los recursos y el vocabulario que utiliza y cómo RDF es uno de los pilares fundamentales para la construcción de Datos Enlazados (Linked Data).Contenido de la Unidad 4 – Parte II
Objetivo:Estudiar la forma en que RDF identifica los recursos y el vocabulario que utiliza y cómo RDF es uno de los pilares fundamentales para la construcción de Datos Enlazados (Linked Data).Contenido de la Unidad 4 – Parte II¿Cómo nombrar los datos en la Web?
RDF: conceptos, sintaxis y semántica
2.1 Definición del modelo abstracto de RDF
2.2 RDF serializaciones
2.3 Representando hechos simples con RDF
2.4 RDF Schema/RDF vocabulario
2.5 Inferencia en RDF
2.6 Semántica de RDF
MATERIAL:**** Capítulos 3, 5 y 6 del libro:
 Allemang, Dean, and James Hendler. Semantic web for the working ontologist: effective modeling in RDFS and OWL. Elsevier, 2011. Accesible en http://www.kevenlw.name/downloads/Ontologist.pdf
Allemang, Dean, and James Hendler. Semantic web for the working ontologist: effective modeling in RDFS and OWL. Elsevier, 2011. Accesible en http://www.kevenlw.name/downloads/Ontologist.pdf ** Capitulo 2 del libro:Foundations of Semantic Web Technologies.
** Capitulo 2 del libro:Foundations of Semantic Web Technologies.
Pascal Hitzler, Markus Krötzsch, Sebastian Rudolph
Textbooks in Computing, Chapman and Hall/CRC Press, 2009.
(accesible en: SWTechnologies.pdf) -
-