Buenas,
A algún otro grupo le pasa que al correr la parte 3 (Modelo neuronal para capturar la semántica) se quedan sin RAM en el colab? Probamos habilitando la GPU y ni aun así pudimos.
Hola Germán,
esperemos que responda el resto de grupos a ver cómo fue su experiencia.
Mientras tanto, les comento que para esta parte es imprescindible que usen una GPU del entorno de ejecución de Colab. La diferencia en el tiempo de ejecución (con y sin GPU) es abismal. Si hay otros grupos leyendo y no pudieron, la forma de activar un entorno con GPU en Colab es:
esperemos que responda el resto de grupos a ver cómo fue su experiencia.
Mientras tanto, les comento que para esta parte es imprescindible que usen una GPU del entorno de ejecución de Colab. La diferencia en el tiempo de ejecución (con y sin GPU) es abismal. Si hay otros grupos leyendo y no pudieron, la forma de activar un entorno con GPU en Colab es:
1) Click en "Conectar" y luego en "Cambiar tipo de entorno de ejecución"

2) Elegir una GPU. En este caso, elegí "T4 GPU".
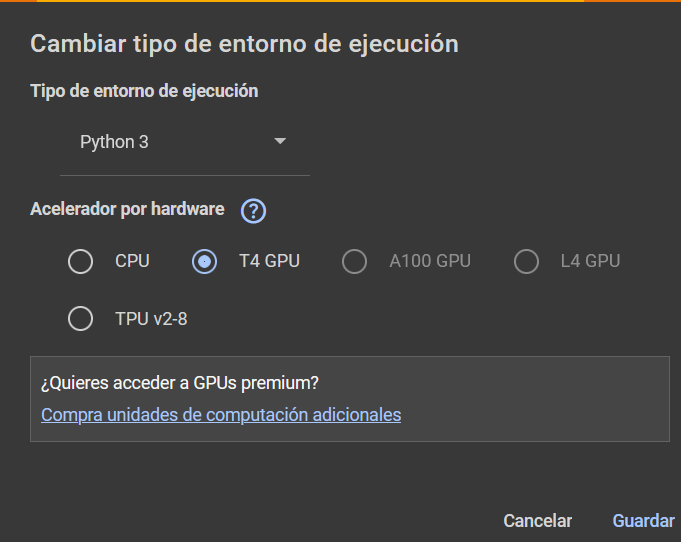
Por las dudas de que Google hubiera cambiado algún detalle de sus recursos disponibles, acabo de intentar correr mi código con una T4 GPU y anda bien (y rápido).
Porfa, manténgannos al tanto de si pudieron correrlo. Saludos,
Santi
Nosotros tenemos activado T4 GPU.
Al intentar correr el código tenemos el siguiente error:
"Tu sesión ha fallado porque se ha usado toda la memoria RAM disponible"
Al intentar correr el código tenemos el siguiente error:
"Tu sesión ha fallado porque se ha usado toda la memoria RAM disponible"
Hola Germán,
lo primero que se me ocurre es que intenten reiniciando el entorno de ejecución y borrando todo lo que tenga guardado.
Lo segundo que se me ocurre es que intenten codificando solamente dos oraciones, y ejecutando la menor cantidad de celdas posible, para intentar rastrear la razón por la que estén obteniendo ese error.
¿Alguien de otro grupo ha tenido esta dificultad?
Santi
Sí, a nosotros se nos corta de la nada la ejecución y nos aparece el mensaje de que quedamos sin RAM
Usando apenas los primeros 10 elementos quiroga_sentences el Collab ya usa casi la mitad de RAM disponible
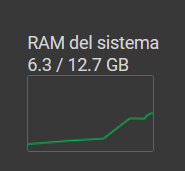
Usando apenas los primeros 10 elementos quiroga_sentences el Collab ya usa casi la mitad de RAM disponible
Buen día,
este es el estado de los recursos al ejecutar mi solución y codificar todas las oraciones de quiroga_sentences.
este es el estado de los recursos al ejecutar mi solución y codificar todas las oraciones de quiroga_sentences.
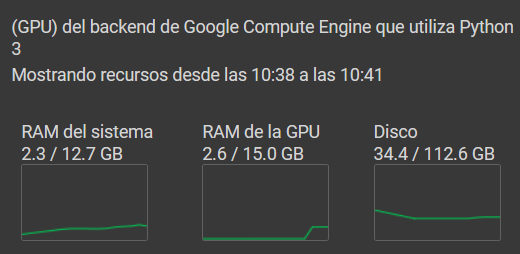
Si les crece tanto la RAM del sistema, y no les crece la RAM de la GPU, puede que el Colab no esté usando la GPU para ejecutar el modelo "intfloat/multilingual-e5-large".
Guíense por esta sección de la model card del modelo en HuggingFace, donde explica cómo usarlo con la biblioteca sentence transformer: https://huggingface.co/intfloat/multilingual-e5-large#support-for-sentence-transformers
Manténgannos al tanto,
Santi
Santi
Hola, yo tuve este problema en Colab, incluso usando T4 GPU y lo que encontré fue que tenes que hacer varias cosas:
1. Procesar las sentencias de quiroga en batch en lugar de todas juntas, usando DataLoader de PyTorch
2. Mover los tensores a la GPU para calcular los embeddings y luego de la GPU a la CPU para liberar memoria
# Mover de GPU a CPU
embeddings_cpu = embeddings.cpu()
3. Decirle explícitamente a pytorch que el modelo usa la GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
https://discuss.huggingface.co/t/is-transformers-using-gpu-by-default/8500/2
Si el docente le parece adecuado, puedo compartir la solución completa.
1. Procesar las sentencias de quiroga en batch en lugar de todas juntas, usando DataLoader de PyTorch
2. Mover los tensores a la GPU para calcular los embeddings y luego de la GPU a la CPU para liberar memoria
# Mover de GPU a CPU
embeddings_cpu = embeddings.cpu()
3. Decirle explícitamente a pytorch que el modelo usa la GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
https://discuss.huggingface.co/t/is-transformers-using-gpu-by-default/8500/2
Si el docente le parece adecuado, puedo compartir la solución completa.
Hola Emi,
sinceramente no sé exactamente por qué a algunos les da ese error y a otros no. Pero, por las dudas, pregunto: ¿Están instalando y usando la biblioteca sentence-transformers? Porque el primer ejemplo que se muestra en la página del modelo no la usa, pero el segundo sí. Debería ser algo así:
!pip install sentence-transformers #instala la biblioteca
from sentence_transformers import SentenceTransformer #importa la biblioteca
model_emb = SentenceTransformer("intfloat/multilingual-e5-large") #instancia un modelo de sentence transformers según "intfloat/multilingual-e5-large"
Si aún así siguen sin poder correrlo, avísennos que podemos rever los criterios del laboratorio junto al resto de los docentes.
¡Ojalá puedan correrlo!
Santi
sinceramente no sé exactamente por qué a algunos les da ese error y a otros no. Pero, por las dudas, pregunto: ¿Están instalando y usando la biblioteca sentence-transformers? Porque el primer ejemplo que se muestra en la página del modelo no la usa, pero el segundo sí. Debería ser algo así:
!pip install sentence-transformers #instala la biblioteca
from sentence_transformers import SentenceTransformer #importa la biblioteca
model_emb = SentenceTransformer("intfloat/multilingual-e5-large") #instancia un modelo de sentence transformers según "intfloat/multilingual-e5-large"
Si aún así siguen sin poder correrlo, avísennos que podemos rever los criterios del laboratorio junto al resto de los docentes.
¡Ojalá puedan correrlo!
Santi