Buen día,
El ejercicio 3 parte 1 del parcial 2014 no entendemos la solución ya que cada fork sin etiqueta vemos que crea 2 procesos.
Buen día,
El ejercicio 3 parte 1 del parcial 2014 no entendemos la solución ya que cada fork sin etiqueta vemos que crea 2 procesos.
Hola Silvia,
La solución lo que dice es lo siguiente: primero etiqueta cada una de las sentencias fork(), de esta manera (con el propósito de identificarlos):
int main() {
fork(); // fork A
fork(); // fork B
fork(); // fork C
printf("P%d", getpid());
return 0;
}
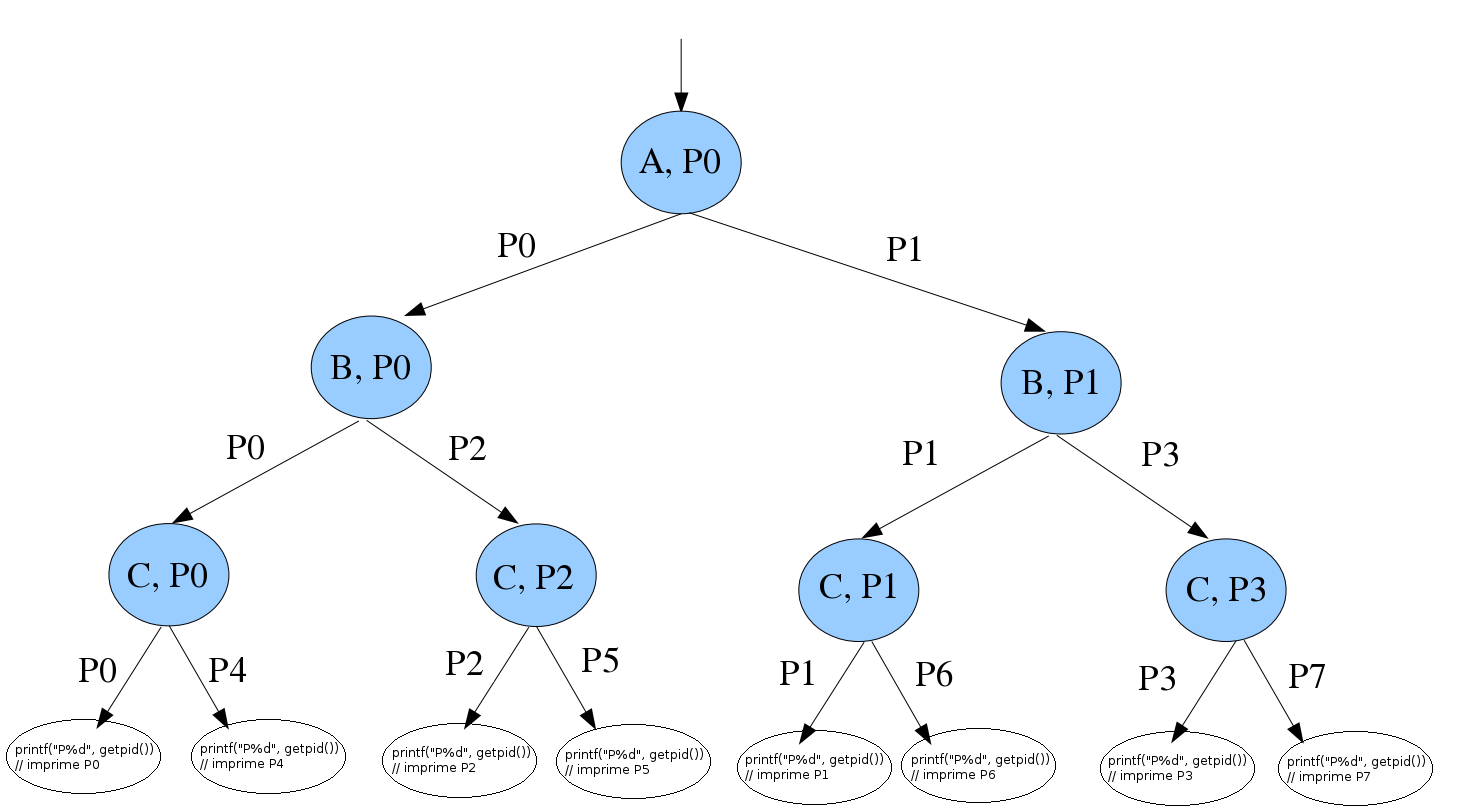
Entonces el proceso inicial, llamémosle P0, cuando ejecuta el primer fork(), o sea, el etiquetado por A, crea otro proceso, que es una copia idéntica de sí mismo (con el mismo código), digamos P1, y ambos (P0 y P1) ejecutan concurrentemente a partir de la siguiente instrucción. De esta manera, el segundo fork(), o sea, el etiquetado por B, se ejecuta en el proceso padre P0, y en el hijo P1, por lo que cada uno de ellos crea a su vez otro proceso hijo. Digamos que P0 crea P2 y P1 crea P3. En consecuencia, a partir del segundo fork(), hay 4 procesos ejecutando concurrentemente: P0, P1, P2 y P3. Por lo tanto el tercer fork(), o sea, el fork identificado por C, es ejecutado en estos cuatro procesos.
El grafo representa cada fork() ejecutado, con un nodo. Entonces con A hay un único nodo, pues el fork A es ejecutado en un proceso solo (el original, o P0). Del fork A salen dos arcos, lo cual quiere decir que a partir de dicho fork, hay dos procesos ejecutando concurrentemente (P0 y P1). Forks B hay dos, uno se ejecuta en el proceso original (P0) y el otro en el hijo recién creado (P1). Para hacer el grafo más claro, voy añadir en cada nodo el nombre del proceso en que es ejecutado el fork, e identificar los arcos con los procesos que ejecutan concurrentemente a partir de dicho fork (sigo la convención de que en cada bifurcación, siempre la arista izquierda representa la ejecución del padre y la de la derecha, la ejecución del hijo).
Agregué también una última sentencia para ver qué se haría en esa situación. Doy a entender que el P0 tiene por pid 0, P1 por pid 1, etc. En realidad, en UNIX, estos pids tan bajos están reservados para procesos del sistema operativo (el 0 es el scheduler y el 1 init, si no me equivoco).
La salida del programa debiera ser algo como:
P0
P1
P2
P3
P4
P5
P6
P7
aunque nada garantiza que la salida sea en ese orden ( podría estar intercambiadas esas líneas, dependiendo del proceso que termine primero, e incluso podría no haber 8 líneas, en caso de que algunos de los padres terminen antes que sus hijos, dado que no hay sentencias wait() ni waitpid() ).
Saludos.
Algo que quería rectificar es que siempre la salida va a ser de 8 líneas, pues se crean 7 procesos (aparte del original) y todos van a ejecutar necesariamente la línea printf("P%d", getpid()). En Perl, un programa equivalente podría ser:
use strict;
use warnings;
use POSIX qw(getpid);
fork();
fork();
fork();
printf "%Pd\n", getpid();
Podemos ejecutarlo desde la consola como
$ perl -MPOSIX -e 'fork; fork; fork; printf "P%d\n", getpid()'
O sabiendo que $-$ es una variable predefinida de Perl que tiene el pid del proceso actual, es equivalente a:
$ perl -le 'fork; fork; fork; print "P$-$"'
Escribo "$-$" con un guión en medio porque de lo contrario el editor me lo toma como un tag para escribir código latex y se ve mal, pero es dos signos de pesos sin guión entre medio. La salida que obtuve, fue:
[pablo@localhost ~]$ perl -le 'fork; fork; fork; print "P$-$"'
P15322
P15323
[pablo@localhost ~]$ P15327
P15326
P15325
P15324
P15329
P15328
Cuando el proceso original no es el último en terminar, la shell imprime el prompt inmediatamente y la salida queda un poco rara :P.
Saludos.