Hola!
No me doy cuenta de una mejora sustancial al hacer elem con foldr y foldl. Es más, creo que me tardan lo mismo aprox. Estuve pensando por qué foldl puede ser más eficiente, y sobre todo en el caso de 1 en [1..10000000], pues foldl comienza del inicio de la lista donde ya se encuentra 1. Sin embargo, veo que tanto foldl como foldr recorren toda la lista, aunque hayan dado con el resultado antes de que termine la recursión.
Quería saber qué tal estaba mi razonamiento y en qué le erro. Les dejo mis implementaciones, las cuales son prácticamente iguales.
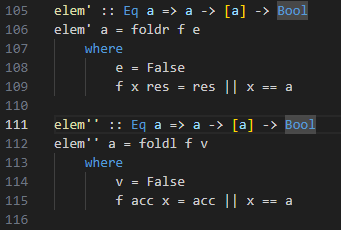
Agradezco cualquier comentario, saludos!