hola,
como dice la letra, los parámetros se reciben por stack. Entonces, cuando se llama la función arboles_iguales, uno debe asumir que los parámetros de la función (nodo* arbol1, nodo* arbol2) se encuentran en el stack. Como en este caso la función la estás llamando vos (recursivamente) tenés que pasarle los parámetros correspondientes. Observar que la primera llamada a la función arboles_iguales, alguien te va a dar los parámetros, como dice la letra (El programa que va a invocar esta función lo hace con el siguiente pseudocódigo: ...).
Entonces, en cada llamada recursiva de árboles iguales es necesario pushear en el stack los punteros a los subárboles correspondientes (nodo* arbol1, nodo* arbol2). En este caso sería
return (arboles_iguales(arbol1->izq, arbol2->izq) && arboles_iguales(arbol1->der, arbol2->der));
donde primero tenes que pushear las ramas izquierdas de ambos árboles y hacer la llamada de la función, y luego pushear las dos ramas derechas y llamar la función nuevamente.
Luego, sabemos que el nodo tiene la siguiente estructura:
typedef struct {
short valor;
nodo* izq, der;
} nodo;
Esto en memoria se vería así:
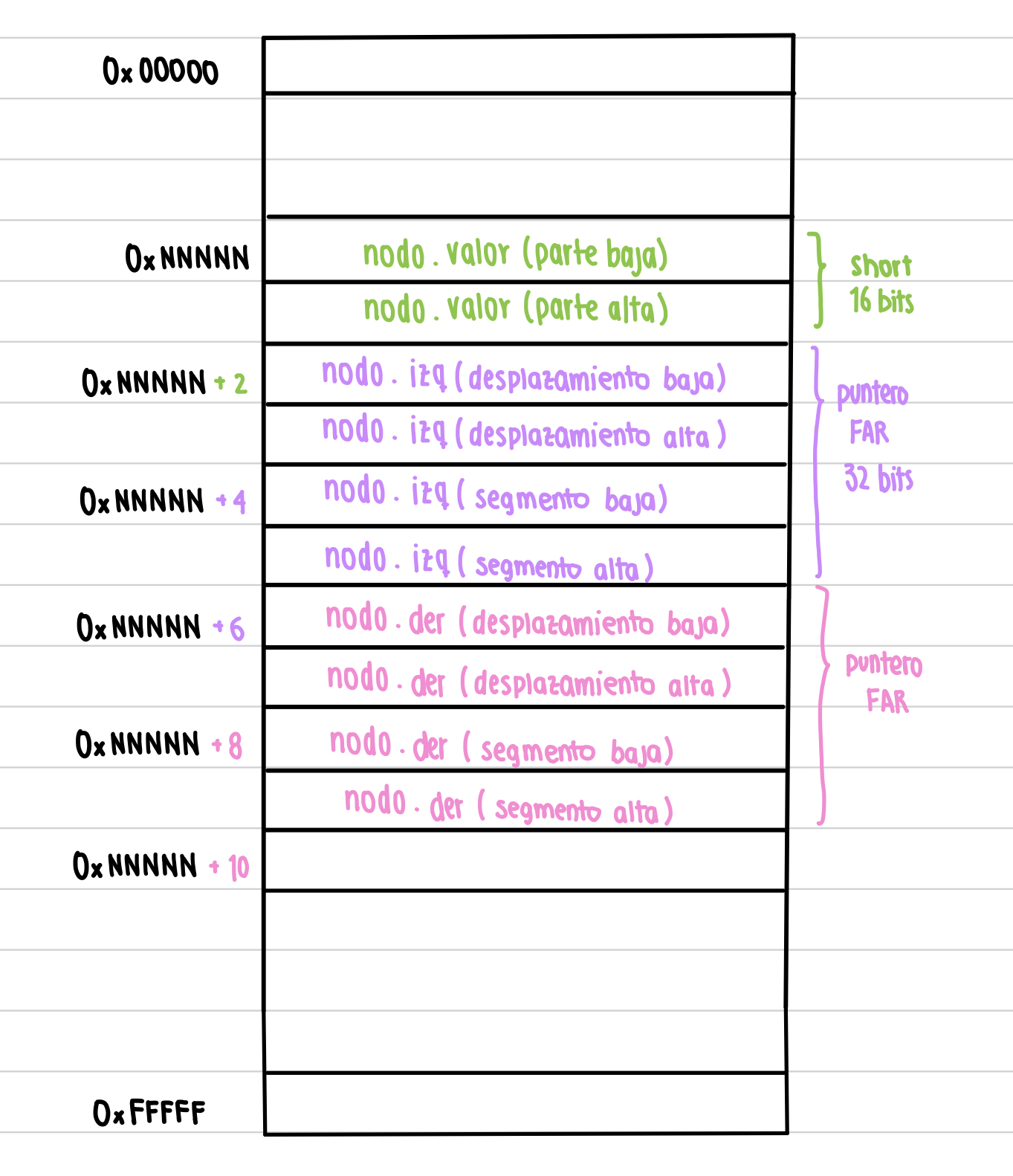
Donde podes ver el valor, el puntero izq y luego el der, representados como punteros FAR, que significa que se encuentran en otro segmento y por ende necesitamos el segmento y el desplazamiento (cuando el puntero es NEAR el puntero está en el mismo segmento y solo se necesita el desplazamiento para representarlo).
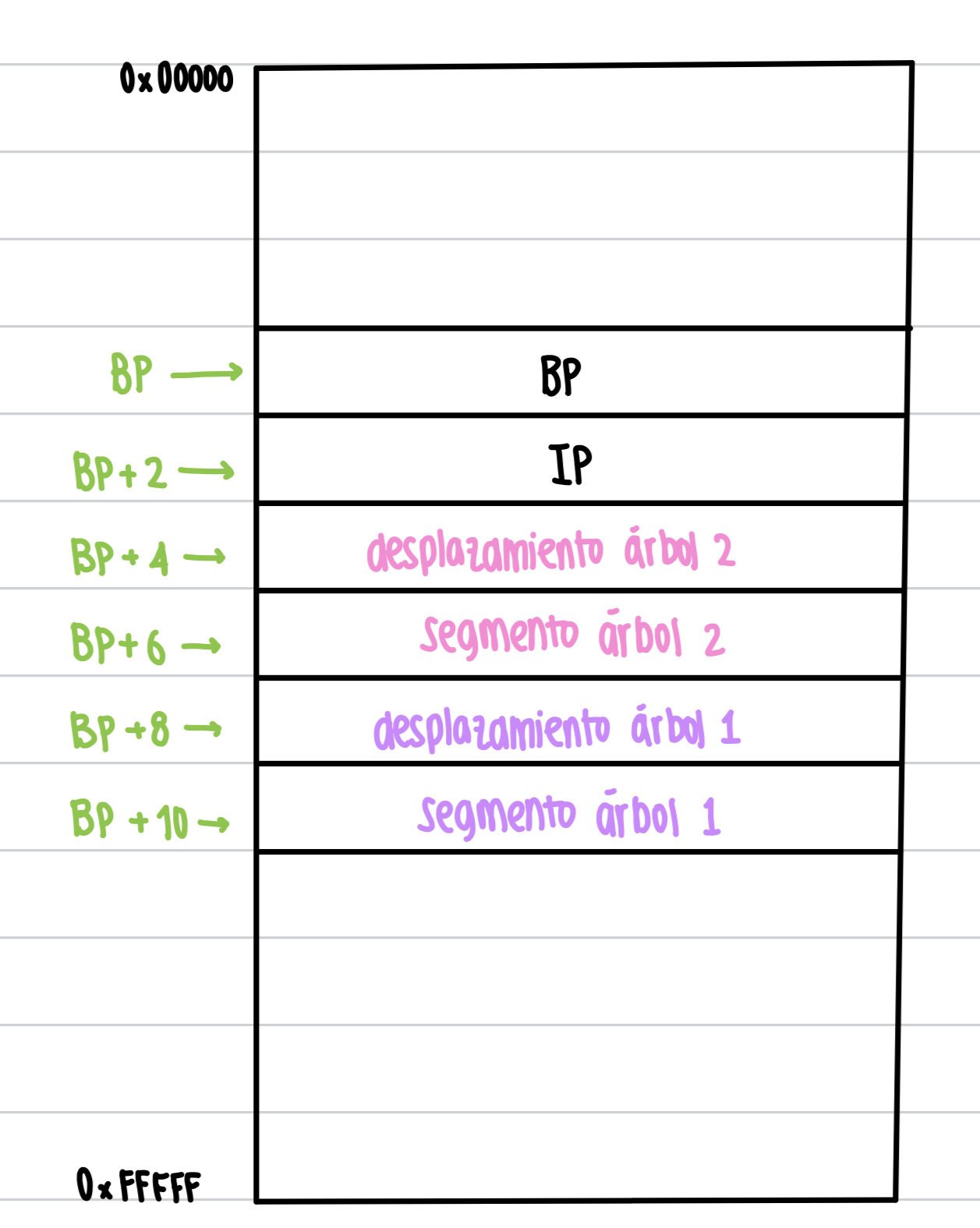
En la llamada inicial al código, y después de pushear BP, tenemos los dos punteros a los árboles originales en el stack, así:
y con el código:
mov BX, [BP+4] ; BX = desplazamiento arbol 2
mov AX, [BP+6] ; AX = segmento arbol 2
mov SI, [BP+8] ; SI = desplazamiento arbol 1
mov CX, [BP+10] ; CX = segmento arbol 1
mov DS, CX ; DS = segm arbol1
mov ES, AX; ES = segm arbol2
se guardan los punteros a estos árboles.
En la llamada recursiva arboles_iguales(arbol1->izq, arbol2->izq) debemos pushear en el stack los parámetros necesarios (los punteros a los dos árboles) de forma que queden como en la última imagen, que es como los espera nuestra función. Primero se pushea la rama izquierda del árbol1, pusheando primero el segmento y luego el desplazamiento. Sabemos que en DS:[SI] se encuentra árbol 1 (DS=segm arb1, SI=desp arb1). Por la imagen 1, sabemos como se dispondrá en memoria este árbol, y por ende sabemos que en DS:[SI+2] se encuentra el desplazamiento del árbol izquierdo y en DS:[SI+4] el segmento, entonces se hace:
PUSH [SI+4]; segmento arb1-> izq (DS segmento implícito)
PUSH [SI + 2]; desplazamiento arb1->izq
Para el arbol 2 es lo mismo, sabemos que en ES:[BX] se encuentra árbol 2 (ES=segm arb2, BX=desp arb2). Sabemos que en
ES:[BX+2] se encuentra el desplazamiento del árbol izquierdo y en ES:[BX+4] el segmento, entonces se hace:PUSH ES:[BX+4]; segmento arb2-> izq (DS segmento implícito)
PUSH ES:[BX + 2]; desplazamiento arb2->izq
la llamada a arboles_iguales(arbol1->der, arbol2->der) es análoga, mirando el dibujo en la memoria (en vez de ser +4 y +2 va a ser +8 y +6) por que acceso a las ramas derechas
espero que quede claro, sino preguntá de nuevo
saludos!


 ¿Esto se puede hacer o es un error?
¿Esto se puede hacer o es un error?