Buenas, en el ejercicio 2 para conseguir la posición en el arreglo en la solución dice que aplica
h(x) % c->cota
La función de hash no daba directamente el índice en el que tenia que buscar el elemento? Por que hace módulo? Gracias
Buenas, en el ejercicio 2 para conseguir la posición en el arreglo en la solución dice que aplica
h(x) % c->cota
La función de hash no daba directamente el índice en el que tenia que buscar el elemento? Por que hace módulo? Gracias
Hola
En general una función de hash debe hacer módulo el tamaño de la tabla para asegurar que se accede a una posición válida del arreglo. El módulo podria hacerse eventualmente dentro de la función de hash si se recibe como parámetro ademas del valor propio un entero para el tamaño de la tabla.
Saludos Carlos
Buenas tardes.
Me pasó que resolví este ejercicio de forma iterativa, pero en la solución del PDF lo hicieron recursivo. La solución del PDF es esta:
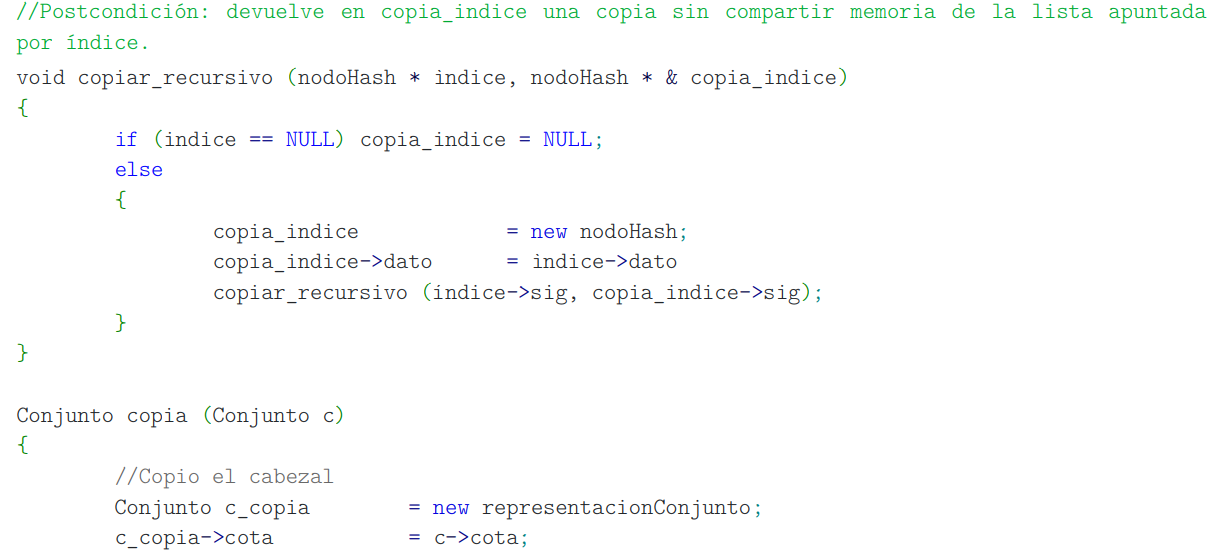

Mientras tanto mi solución es la siguiente:
La solución que plantea la compañera tiene un par de errores (por ejemplo, siempre crea un nodo nuevo, por lo que seguramente le quede memoria colgada). Más allá de eso, yo también quise optar por una solución iterativa sin función auxiliar y me topé con un par de inconvenientes. Dejo acá algún código y mis comentarios por si a alguien más le sirven.
La solución iterativa naíf te complica un poco porque tenés dos particularidades que hay que tratar con cuidado: si la entrada de c->tabla[i] es NULL hay que asignar NULL a res->tabla[i] y no hacer más nada. En caso contrario hay que primero crear un nodo y asignarlo a res->tabla[i], y de ahí iterar con un puntero auxiliar para copiar el resto de la lista:
Conjunto copiar_101(Conjunto c) {
Conjunto res = new representacionConjunto;
res->cota = c->cota;
res->cantidad = c->cantidad;
res->tabla = new struct nodoHash *[res->cantidad];
for (int i = 0; i < c->cantidad; i++) {
struct nodoHash *t1 = c->tabla[i];
if (t1 == NULL) {
res->tabla[i] = NULL;
} else {
res->tabla[i] = new struct nodoHash;
res->tabla[i]->dato = t1->dato;
struct nodoHash *t2 = res->tabla[i];
t1 = t1->sig;
while (t1 != NULL) {
t2->sig = new struct nodoHash;
t2 = t2->sig;
t2->dato = t1->dato;
t1 = t1->sig;
}
t2->sig = NULL;
}
}
return res;
}
Una alternativa más corta (aunque requiere algo más de familiaridad con la manipulación de punteros) es usar un puntero indirecto. Acá t2 es un puntero a un puntero a un nodoHash. Apunta primero al puntero que está en el array tabla de res. Si t1 es NULL no se entra al while. De lo contrario, se crea un nuevo nodo dentro del while, se le carga el dato y se asigna a lo apuntado por t2. Luego se le asigna a t2 un puntero al sig del nuevo nodo, y se actualiza t1 como siempre. Al salir se asigna NULL a lo apuntado por t2, lo que marca el final de la lista, sea que esta tiene elementos o no:
Conjunto copiar_indirecto(Conjunto c) {
Conjunto res = new representacionConjunto;
res->cota = c->cota;
res->cantidad = c->cantidad;
res->tabla = new struct nodoHash *[res->cantidad];
for (int i = 0; i < c->cantidad; i++) {
struct nodoHash *t1 = c->tabla[i];
struct nodoHash **t2 = &res->tabla[i];
while (t1 != NULL) {
struct nodoHash *nuevo = new struct nodoHash;
nuevo->dato = t1->dato;
*t2 = nuevo;
t2 = &nuevo->sig;
t1 = t1->sig;
}
*t2 = NULL;
}
return res;
}
Podría no haberse usado la variable nuevo. El while quedaría:
while (t1 != NULL) {
*t2 = new struct nodoHash;
(*t2)->dato = t1->dato;
t2 = &(*t2)->sig;
t1 = t1->sig;
}
No lo revisé en profundidad pero creo que algo similar se podría haber hecho con la función eliminar().
Otra alternativa sería usar una implementación de lista enlazada que simplificara las operaciones de borrado. (Acá lo que más molesta es el tratamiento especial del bucket, el puntero que está en el array.) En el capítulo de hashing del Weiss se implementan todas las listas con header (el primer nodo siempre está y se ignora) y se hace la siguiente salvedad:
If the repertoire of hash routines does not include deletions, it is probably best to not use headers, since their use would provide no simplification and would waste considerable space.
La letra de los parciales que he visto no especifica qué variante de implementación de lista encadenada se ha de usar, pero todas las soluciones asumen que es un puntero al primer elemento (o NULL si es vacía). ¿Se puede proponer una solución en base a otra implementación (más conveniente)?