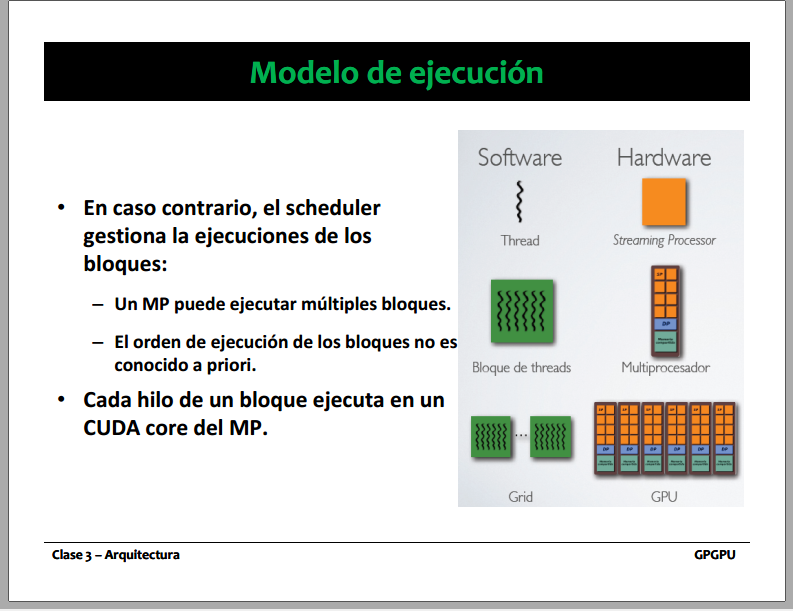
- La arquitectura Fermi tiene 16 multiprocessors
- Cada MP tiene 32 cores, dividido en dos bloques de 16, con un warp scheduler para cada bloque
Entonces la pregunta es
- Los bloques del grid se reparten entre los cores o entre los mp? Porque la imagen 1 da a entender que se reparten entre los cores
- Con cuantos hilos trabaja un core de forma concurrente? Imagen 2 dice que cada hilo se ejecuta en un core, como un warp tiene 32 hilos podría darle un hilo a cada core del MP, pero sin embargo tengo dos warp schedulers en un MP, para que tengo dos si solo trabajo con un warp?
Entonces, dada la arquitectura fermi, si yo pongo a correr un programa con suficientes grids, blocks, etc y pauso la ejecución...
Dentro de un MP:
Con cuantos warps esta trabajando de forma concurrente? y dentro de un warp, cuantos cores se estan encargando de su ejecucion?
La unica forma que todo tenga sentido para mi es que un MP tenga capacidad de manejar dos warps al mismo tiempo ( eso justificaría los dos warp schedulers) y a su vez cada core trabaje con dos hilos (tengo 16 cores para 32 hilos del warp)
Por ultimo,
Como se relaciona todo con los conflictos de bancos en memoria compartida? Si los conflictos de bancos ocurren a nivel de half warp (16 hilos) está relacionado con que hallan 16 cores en un bloque de MP?
Por qué la divergencia se da a nivel de warp y no a nivel de half warp? Es un tema de como decidieron agrupar los hilos para una misma instrucción?
Imagen 1
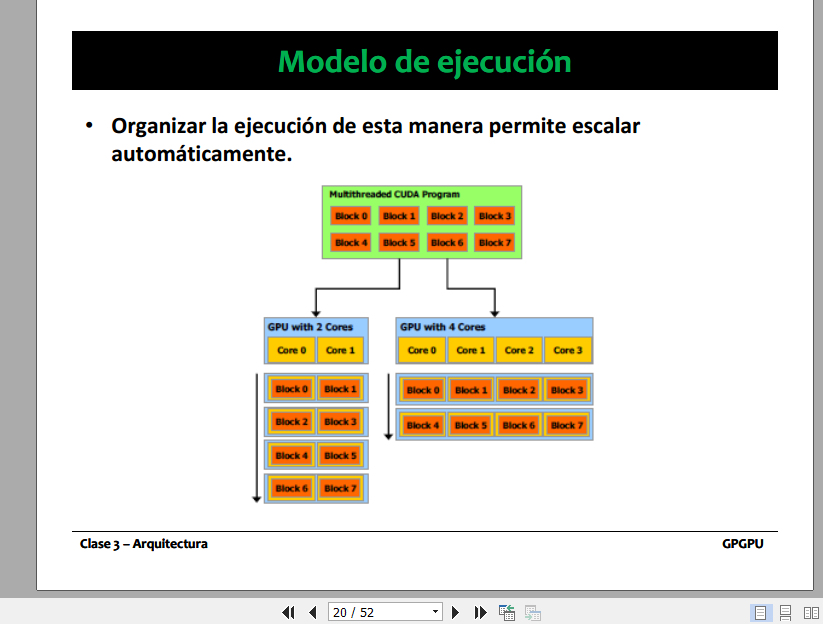
Imagen 2