2.3 Diferencias entre un grafo de conocimientos y un grafo de datos
Perfilado de sección
2.3 Diferencias entre un grafo de conocimientos y un grafo de datos
2.3 Diferencias entre un grafo de conocimientos y un grafo de datos
Según M. Nickel, K. Murphy, V. Tresp and E. Gabrilovich en su artículo A Review of Relational Machine Learning for Knowledge Graph (2016 [2]) definen un Grafo de Conocimientos como:
" [...] un grafo de conocimientos es un grafo estructurado que representa bases de conocimientos (KBs) que
almacenan información factual en forma de relación entre
entidades".
Esta definición de grafo de conocimientos se puede visualizar como un grafo de datos destinado a acumular y transmitir conocimientos del mundo real, cuyos nodos representan entidades de interés y cuyas aristas representan las relaciones entre estas entidades.
El grafo de datos se ajusta a un modelo de datos basado en un grafo, que puede ser un grafo dirigido con aristas etiquetadas, un grafo de propiedades u otro tipo de grafo. Por conocimiento, se hace referencia a algo que se conoce. Esos conocimientos pueden acumularse a partir de fuentes externas o extraerse del grafo de conocimiento en sí mismo. El conocimiento puede estar compuesto por simples declaraciones, como "Montevideo es la capital de Uruguay", o declaraciones cuantificadas, como "Todas las capitales son ciudades". Declaraciones simples pueden acumularse como aristas en el grafo de datos. Para que el grafo de conocimientos pueda acumular declaraciones cuantificadas ("Todas las capitales son ciudades"), entonces es necesaria una base de conocimientos.
Al hablar de una base de conocimientos se hace referencia a que se utilizan métodos deductivos para derivar y acumular más conocimientos (por ejemplo, a partir de que "Montevideo es una capital" y que "Todas las capitales son ciudades" entonces se deriva que "Montevideo es una ciudad"). Esta es la gran diferencia entre un grafo de datos y un grafo de conocimientos.
El grafo de conocimientos tiene además del grafo de datos un mecanismo que le permite hacer inferencias. Las inferencias pueden ser inductivas utilizando redes neuronales o deductivas, utilizando bases de conocimientos.
-
El grafo de conocimientos tiene además del grafo de datos
un mecanismo que le permite hacer inferencias.
La utilización de mecanismos de inferencias a partir de un conjunto de hechos o afirmaciones nos permite hacer explícito conocimiento
implícito. Este mecanismo es fundamental para lograr capturar los componentes que hacen a la semántica de los datos en la Web Semántica o Web de Datos.
En la Web Semántica es necesario además tener mecanismos para poder desambiguar las entidades, "Montevideo es una ciudad" pero también "Montevideo es un departamento". O para entender el significado del concepto "Jaguar" (con sus posibilidades de ser comprendido como auto o como animal) es necesario primero comunicarlo utilizando símbolos de un lenguaje. Luego que lo conseguimos comunicar decimos que "se entiende" si se interpreta correctamente la información del contenido del recurso o del mensaje comunicado.
Para interpretar correctamente un concepto es importante: tener elementos del contexto, tener experiencia con el uso del concepto y comprender la pragmática (intención del que envia el mensaje o crea el contenido). Estos elementos se describen en el llamado Triángulo Semiótico de Ogden et. al [3]. La Figura 4 nos muestra el triángulo semiótico para el concepto "jaguar".
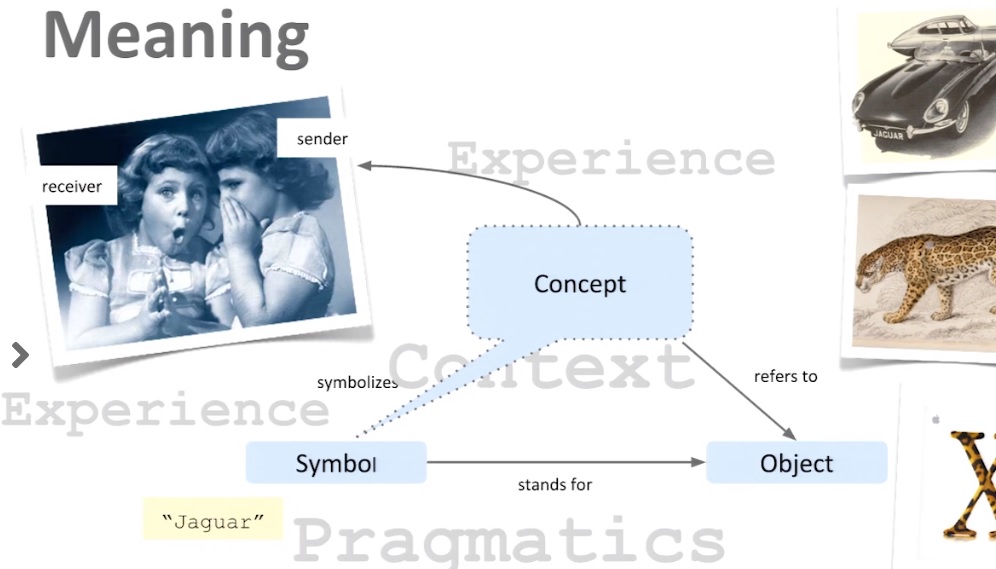
Figura 4.
Ejemplo de Triángulo Semiótico. (Tomado
de presentación
de Dr. Harald Sack –
FIZ Karlsruhe.)
La tercera generación de la web, la Web 3.0 es la Web Semántica, también llamada la Web de Datos, no sólo datos leídos, decodificados, por programas sino "entendidos", interpretados correctamente por programas.
Para lograr la interpretación correcta de los datos de la web por programas necesitamos encontrar, según el triángulo semiótico, su pragmática, su contexto y sus experiencias de uso. Estos temas junto con el análisis de su sintaxis son temas de estudio ampliamente tratados por el área de Procesamiento de Lenguaje Natural (NLP de su siglas en inglés).
Otra forma, complementaria al NLP, consiste en expresar de manera explícita la semántica de los datos expresando explícitamente con metadatos la pragmática, contexto y experiencias de uso de los datos. Este enfoque corresponde a la aplicación de técnicas de la Web Semántica utilizando grafos de conocimientos, en particular grafos RDF.